Messy Data
For most research purposes, "messy" data spells trouble. If some items in a database do not contain any information for a particular field (e.g., if some items in a demographic database do not contain information about a person's age), that item cannot be included in operations that depend on the information in that field. And if the information in a given field is not entered in a consistent manner across all items (e.g., if references to West Virginia are entered variously as "WV," "West Virginia," and "WVa"), many operations such as searches on key terms will yield incomplete and inaccurate results.
Messy data presents ethical as well as practical challenges. For some analyses, data must be "cleaned up" (meaning anything from regularizing spelling to correcting apparent errors). And if the data originated directly from subjects, altering their original data changes not only the usefulness but also the nature of the information. The effects of any such alteration of original data on analysis must be considered and accounted for in any argument based on that data. Given the manner in which narratives and associated metadata are contributed to the DALN, the archive presents many such challenges—and associated opportunities.
First, consider the "raw" metadata for the first 2,657 narratives in the DALN ( to consult the raw data as you read this section, open the file DALN_RawData_111120.csv, which can be opened in or imported into Excel and most other spreadsheet and database applications). Here, readers must bear with a review of some technical details that will make the toolbox files easier to understand and use. Each record (row) in the raw metadata relates to a single literacy narrative and contains 77 separate fields (columns) of information, some generated by the database (e.g., the item ID and the date on which the item was accessioned), some supplied by the contributor of the narrative (e.g., the title and description of the narrative). Most of the field values consist of the characters "dc" followed by one or more words separated by periods, indicating that the information in those fields is related to the categories of information specified in the Dublin Core Metadata Element Set, allowing the database to share information more easily with other databases that employ—or whose interfaces understand—the Dublin Core standard (see Figure 1).
to consult the raw data as you read this section, open the file DALN_RawData_111120.csv, which can be opened in or imported into Excel and most other spreadsheet and database applications). Here, readers must bear with a review of some technical details that will make the toolbox files easier to understand and use. Each record (row) in the raw metadata relates to a single literacy narrative and contains 77 separate fields (columns) of information, some generated by the database (e.g., the item ID and the date on which the item was accessioned), some supplied by the contributor of the narrative (e.g., the title and description of the narrative). Most of the field values consist of the characters "dc" followed by one or more words separated by periods, indicating that the information in those fields is related to the categories of information specified in the Dublin Core Metadata Element Set, allowing the database to share information more easily with other databases that employ—or whose interfaces understand—the Dublin Core standard (see Figure 1).
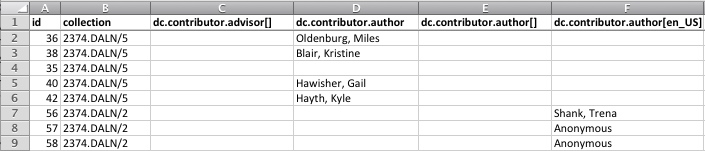
Figure 1. Column headers showing extended Dublin Core metadata field names.
So, for instance, the fields that begin with "dc.contributor" should identify "an entity responsible for making contributions to the resource." Additionally, many field names in the DALN contain a third term, a feature of "extended" Dublin Cord metadata that allows databases to draw finer distinctions than can be made using the fifteen basic Dublin Core elements. Finally, many of the fields in the DALN appear in three variations designated by a code in square brackets following the field name (e.g., [], [en], [en_US]). These variations reflect the internal structure of the DSpace repository platform on which the DALN is built, not any deliberate distinction made by contributors or the DALN administrators (neither of whom can "see" these distinctions in standard user or administrative interfaces).
A closer look at some of the data reveals several caveats and opportunities for analyzing the DALN. Suppose you were interested in the gender balance among contributors. You decide to search, but the site doesn't tell you what controlled vocabulary, if any, has been used to describe gender in the database, so you guess. Separate searches on the terms "male" and female" using the Quick Search field on the DALN home page (http://daln.osu.edu) yield (as of this writing) 741 returns for "male" and 1,198 returns for "female." From those results, we might assume that, indeed, "male" and "female" are the correct search terms and that 62% of the narratives in the DALN were contributed by women and 38% by men. A savvy user might wonder exactly what the Quick Search field searches and try the same search using the Advanced Search link. The user would find that searches cannot be restricted to gender, but he or she might try the search on another of the options provided, such as author (which in fact searches a subset of fields, including the author's name). This search on "male" and "female" yields only slightly different results (1190 for "female" and 732 for "male"). An especially curious user might wonder whether other categories for gender are represented in the database, but without a list of terms that contributors actually used in the database, he or she would have to proceed by trial and error, never knowing whether all gender terms used in the database had been searched. Further, the search interface does not currently indicate that the values in the fields have been recorded exactly as entered by contributors, so users might not think to search for alternative wording or spelling. Browsing the DALN by subjects using the links on the home page turns out not to help with this problem because the subject terms are not recorded in the same field as gender.
If the searcher were also a contributor to the DALN, he or she might think to review the prompt on the submission form that asks contributors for information about their gender. Here is what he or she would find in the online form (see Figure 2):

Figure 2. The prompt in the online submission form for information about a contributor's gender.
A paper version of the form is worded similarly:
Do you want to self identify with regard to gender (ex. Female, male, transgendered? (This information will help other DALN users find stories by people of a particular gender.)
These prompts reveal two important facts. First, both submission forms suggests "male," "female," and "transgender(ed)" as options. Second, supplying information about the contributor's gender is optional. At this point, the searcher would have exhausted all of the information available through the current database interface. Consulting the full metadata provided with this essay considerably refines—and complicates—our conjectural question about gender representation in the DALN.
In order to explore the complete DALN metadata related to gender, we first have to aggregate some related fields/columns on the spreadsheet. Because the distinctions among dc.creator.gender[], dc.creator.gender[en], and dc.creator.gender[en-US] are unimportant—the values in those fields were entered in response to the same question, and any given narrative will have a value for only one of the fields—we first have to collapse those three fields to a single field. Once we have done so, we can generate a table that lists all of the distinct values entered into the gender field, the number of times each value appears, and the percentage of all responses that a specific response represents. See the toolkit file DALNData_110816GenderRaceClass.xlsx, in which fields for gender, race, and socioeconomic class have been aggregated and summary tables for each resulting field have been generated (click on the tabs at the bottom of the spreadsheet window to view tables for gender, race, and class, respectively).
It turns out that the 2,359 contributors represented in the data used 39 distinct responses to describe their genders, including 10 that include multiple responses associated with the same narrative, either because an individual described him- or herself using several terms or because the narrative was contributed by two or more people (the submission process provides only one form per narrative, but groups can provide multiple responses to most questions—which, for instance, is why you will find narratives with multiple years of birth indicated). The precision of the figures in the table shouldn't deflect us from multiple interpretive problems. We can see at a glance that nearly 18% of contributors provided no information about their gender. Were they deliberately suppressing that information or simply choosing not to fill out any more of the form than necessary, perhaps because they were short on time? More importantly, the table highlights two broad problems we face anytime we think categorically about people. On the one hand, we run the risk of lumping significant differences into the same category—comparing apples and oranges, as it were. In the gender table, for instance, under what circumstances, if any, would it be appropriate to combine the categories "Female - Male to Female Transexual" and "transgender, non op mtf" for the purpose of reporting numbers or percentages of responses? On the other hand, categorization runs an equal risk of making distinctions where there is no significant difference. For instance, in an attempt to simplify the data, we might safely lump together the responses "F," "femal," "Female," when categorizing responses, but what about "Lesbian female," which combines gender and sexual orientation? And do we lump "inappropriate" responses (e.g., "sure. why not?" and "Yes") with null responses?
Problematic as this "messy" data might be in certain circumstances, it also reminds us of—and confronts us with—the complexity of human gender. Providing contributors with several standard responses and a text field for "other" responses might yield cleaner data while allowing for diverse responses, but that approach also reifies the standard responses more emphatically than a list of examples intended to clarify the nature of the question (i.e., distinguishing between gender and sexual preference). Additionally, standard responses may elide significant differences in the way that contributors characterize information about themselves. Reading the database and discovering the complex variety of self-identifications contained in the DALN metadata can help us read individual narratives in a manner that reflects that complexly in the context of literacy narratives composed for the DALN.
Consider further the "RaceEthnicity" tab in the DALNData_110816GenderRaceClass.xlsx spreadsheet, which reflects the same data used in the discussion of gender above. Two differences between this table and the one for gender stand out. First, five times as many distinct terms for race/ethnicity than for gender emerge from the data—perhaps unsurprising in the abstract, but interesting when we consider that 55 of those terms include the term "American" qualified by some other term, revealing a rich diversity of racial and ethnic self-identification associated with being "American." Secondly, almost three times as many (52% of) contributors chose to leave this field blank as chose not to provide information about gender (a pattern closer to that of contributors who chose not to provide information about their socioeconomic class (65%)—see the "Class" tab on the spreadsheet). With allowances for the difficulty of aggregating contributors' varied terms for racial and ethnic identity, we find that of the 1,125 contributors who provide information about their race/ethnicity, 6.87% describe themselves as "African American," 2.92% as Black, and 0.72% employ both terms. Similarly, 14.75% describe themselves as "White" or "White/Non-Hispanic," 10.26% as "Caucasian," and 0.38% use both terms. As used by contributors in this circumstance, do the terms "African American" and "Black," or "Caucasian" and "White," represent merely arbitrary choices among terms in wide circulation, or would their choices correlate with features of their literacy narratives? Examination of those sorts of questions must remain the province of close, critical reading of the narratives, articulated with the self-representation of contributors revealed by reading the DALN metadata.
So far in this consideration of reading the DALN database, we have not altered any data, other than aggregating duplicative fields (one of the steps in "normalizing" data, in the language of database management), and we have employed only those analytical tools commonly provided by spreadsheets: sorting, counting, filtering, and so on. Other tools can help us see and explore additional dimensions of reading the DALN.
Explore the Data: Messy Data
Select a term from the list below to generate a list of narratives from the DALN in which the contributor used that term to describe his or her gender. You can also explore the how contributors self-identify by race, class, and gender by downloading DALNData_110816GenderRaceClass.xlsx from the DALN Database toolkit.