Multifaceted Data
Most visitors will undoubtedly read the narratives in the DALN primarily as oral history, seeking evidence about the individual practices and values and cultural forms that shape, enable, and constrain individuals' and groups' literacies. Many readers will perhaps focus on the structure, rhetoric, and pragmatics of personal narrative, seeking evidence of how narrative structures and shapes our experience, memory, identity, and presentation of ourselves and our experiences to others. Some may be interested, as well, in the linguistic resources upon which people draw when they talk about their literacies. The DALN provides at least three sorts of data for exploring such questions.
The simplest set of linguistic data associated with the narratives consists of the subject terms contributors are asked to submit when they contribute narratives. While the DALN's built-in browse tool on the home page allows visitors to browse the subject terms provided by contributors, it does not provide information about how many narratives are associated with each subject term, except by clicking on the term and searching the DALN.  The Toolkit file DALN_Subjects_Alpha.html provides a more convenient tool for browsing subject terms, providing visual information about the frequency with which each term appears in the database as well as arranging all the terms alphabetically on a single page.
The Toolkit file DALN_Subjects_Alpha.html provides a more convenient tool for browsing subject terms, providing visual information about the frequency with which each term appears in the database as well as arranging all the terms alphabetically on a single page.
The titles that contributors assign to their narratives constitute somewhat more complex linguistic data. The submission process requires contributors to supply titles for all narratives, so that metadata field is perhaps the most often "populated" with data—other than fields automatically populated by the database (such as the data on which a narrative is contributed). Of course, we should keep in mind that 19 titles, as of this writing, are listed as "Untitled," and 72 sport the generic title "Literacy Narrative." Other titles are equally generic, but the vast majority of titles contain more specific wording.
Readers interested in the much-debated question of how widely we can apply the concept of literacy to domains other than reading and writing in natural languages might find it interesting to analyze the titles of narratives in the DALN. The file LiteracyClusters.xlxs in the DALN Database Toolbox provides three views of DALN titles. The first tab, "DALNTitles," lists all titles used at the time the spreadsheet was compiled; the second tab, "3Clusters-Literacy," reports the frequency with which all clusters of three words containing the word "literacy" appear in the full list of titles; and the third tab, "Literacy Phrases," highlights some phrases of interest.3 For example, our contributors' titles modify "literacy" with 34 different preceding nouns and adjectives, from familiar phrases such as "Adult Literacy" and "Early Literacy" to "iPhone Literacy" and "Restaurant Literacy." The titles contain 21 different phrases linking "literacy" with another term using the conjunction "and," from "Literacy and access" and "Literacy and Grief" to "Literacy and Writing." Another 9 titles link "literacy" with another term using the preposition "in," from "Literacy in Athens" to "Literacy in Public." By themselves, such lists tell us little about how contributors understand literacy, but read in conjunction with the search engine in the DALN, these analyses may lead us to read narratives in relationships to one another that we might not otherwise consider, or pursue questions that we might not otherwise ask.
Of course, the DALN contains even richer data for textual analysis in the narratives themselves. And thanks to generous assistance from the TranscribeOhio program and many individual contributors and interviewers, over 450 of the audio and video narratives have been transcribed and, along with the narratives submitted in text formats, can be studied with text analysis software. Because no simple mechanism exists for downloading all of the narratives in text formats, we have provided in the DALN Database Toolkit several corpora of transcripts related to distinct subgroups of narratives, including the Literacy Narratives of Black Columbus project (127 transcripts), narratives contributed at the University of Arkansas at Little Rock (146 transcripts), narratives contributed at the University of Illinois (58 transcripts), and narratives contributed at the 2009 Conference on College Composition and Communication (82 transcripts).
The Literacy Narratives of Black Columbus (LNBC) corpus might inform current efforts to record literacy narratives by members of Black churches in Columbus, Ohio. Facilitators might want to study the use of terms such as "church," "churches," "bible," and "faith" in the corpus. A concordance plot of those terms in the LNBC corpus show that one or more of the terms appears in 42 of the 127 transcripts, and allows users to see where, and how often, those terms appear in each transcript (see Figure 6). A standard concordance display allows users to scan keywords in context and then open relevant transcripts for reading (see Figure 7). Freeware, cross-platform text analysis tools such as AntConc allow users to work on their desktops, and Sites such as Hermeneuti.ca offer an array of textual analysis tools via the Web (see Figure 8). Both tools can be used with the transcript files in the DALN Database Toolkit as complements to close reading of individual narratives, allowing readers to follow themes across narratives that they might otherwise not consider together.
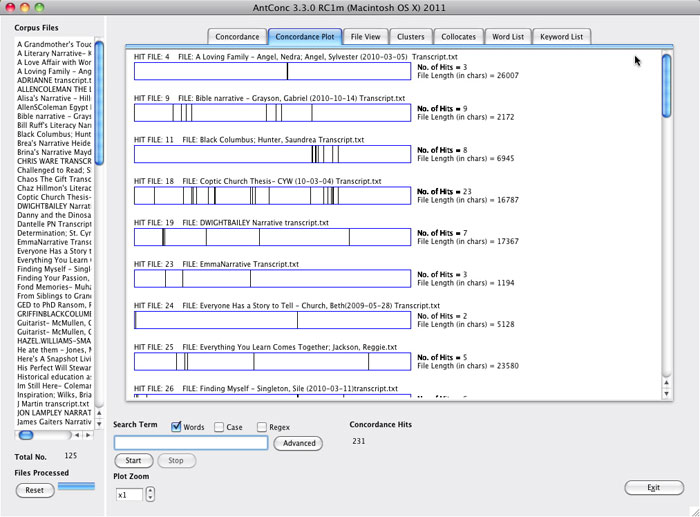
Figure 6. A concordance plot of the terms "church," "churches," "bible," and "faith" in transcripts of 125 narratives in the Literacy Narratives of Black Columbus collection.
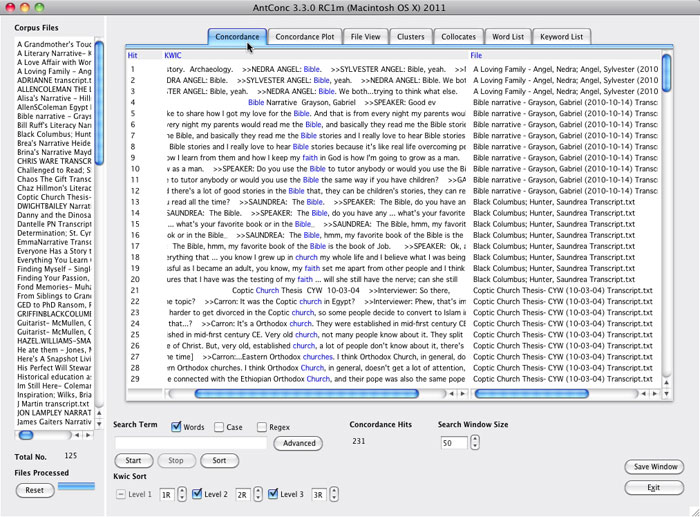
Figure 7. A standard keyword in context (KWIC) report on the terms "church," "churches," "bible," and "faith" in 125 transcripts of narratives in the Literacy Narratives of Black Columbus collection.
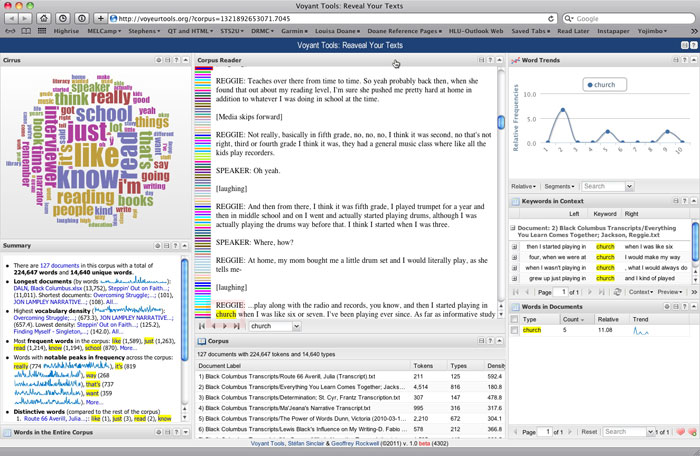
Figure 8. A "dashboard" view of the Voyant Tools loaded with 125 transcripts of narratives from the Literacy Narratives of Black Columbus collection.
3. The lists on the "3Clusters-Literacy" and "Literacy Phrases" tabs were compiled using AntConc, a free text analysis program available at http://www.antlab.sci.waseda.ac.jp/antconc_index.html. Return to text.